
11 Data Structures Powering Database
And why they matter more than you think!

Databases often employ a number of specialised data structures to ensure high performance storage and retrieval of data. While there exists thousands of databases in the wild, there are only a handful of data structures powering them all!
In this blog post, we are going through 11 such data structures. We will talk about the features of that data structures, why & how they are used in database engines, and which famous databases use them internally.
Let us get started then!
Hash Indexes
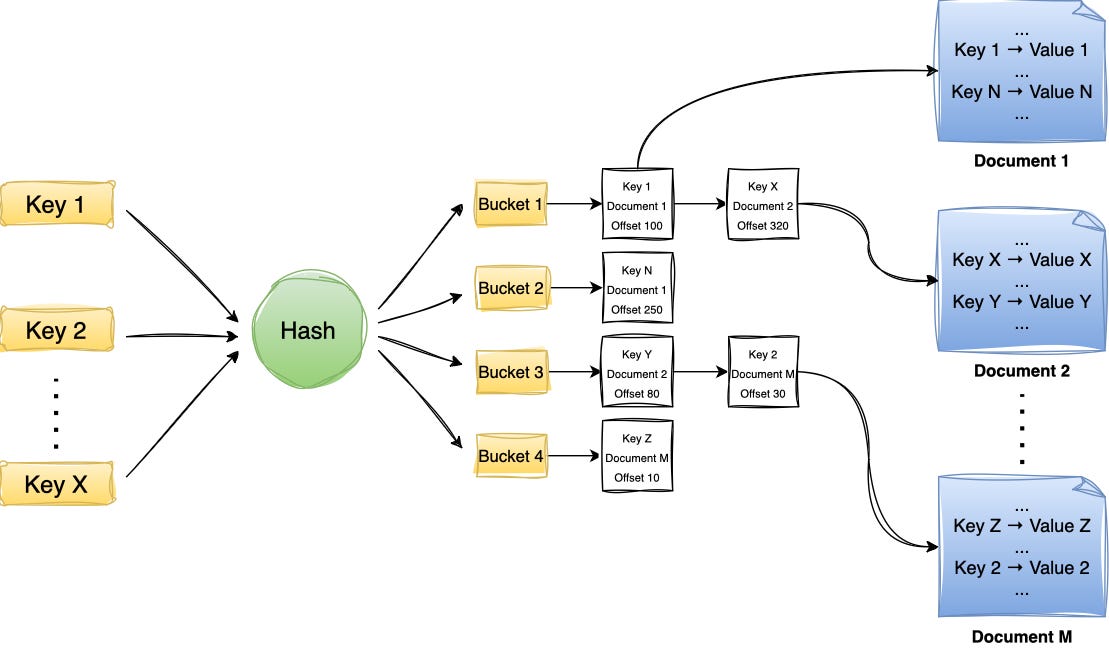
Hash indexing is a technique that uses an in-memory Hash Map to enable fast key lookups. Each key is hashed and mapped to a disk pointer, allowing the system to directly fetch the corresponding value with a single disk seek.
A big disadvantage of Hash indexing is the fact that the entire structure needs to be maintained in memory. If the number of keys is too large to fit in the memory, hash indexes won’t work!
Some of the famous databases that uses Hash Indexes includes ~
Skip Lists

Skip list is a probabilistic data structure that provides efficient search, inserts, and delete in a sorted linked list. All the operations can be performed in O(log N) time compared to O(N) it takes in a simple linked list.
As shown in the illustration above, sparse levels of Linked List are created to assist in quick searches eliminating the need for a sequential search.
Because skip lists store data in sorted order, they are most commonly used in databases for managing Memtables, which we’ll discuss in the upcoming sections.
RocksDB is a great example of a database where Skip Lists are used as Memtables!
Inverted Indexes

Inverted indexes are a common tool for databases that support text based searches. It divides text into individual words and constructs a word to document ID index. This allow quick searches for document containing certain words or patterns.
Elastisearch database is the most popular example that uses inverted indexes to power its full-text search capabilities.
B-Trees

B-Tree is un-arguably the most popular data-structure when it comes to databases. It is a self-balancing tree structure that maintains sorted data on disk and allows searches in logarithmic time complexity.
The key feature of B-Tree is its ability to store more than one key inside a single node that essentially reduces the number of disk seeks.
Almost all relational databases use B-Trees!
Bloom Filters

Bloom filter is yet another probabilistic data structure that is used to test whether a data entry exists in the database before we actually start looking for it. The way Bloom filters are designed, they can give false positive but they can never give false negatives.
Bloom filters are most commonly used in LSM-Tree based databases where a non-existent key could lead the database to search all segments! Instead, if a bloom filter is used before going through the segments, the time taken to search for non-existent keys is improved drastically.
A good example of this case is Cassandra that uses bloom filters in read path to ensure non-existent keys can be responded to quickly!
MemTable

MemTable is an in-memory data-structures that is used to hold reads and writes until they are flushed to disk based SSTables (more on them in the coming section).
MemTable handles both read and write operations: new writes are always inserted into the memtable, while reads must query the memtable first before checking the SSTable files, as the data in the memtable is newer. When a memtable becomes full, it is marked as immutable and replaced by a new one. A background process then flushes the contents of the memtable to an SST file, after which the old memtable can be safely discarded.
There are several ways in which a MemTable can be implemented!
RocksDB and LevelDB are some examples of databases that uses a MemTable.
BitMap Indexes

BitMap indexes uses bitmaps (or, simply put, array of 0s and 1s) to efficiently store and query data. It is particularly useful for columns with low cardinality of distinct value set.
Bitmap indexes use a series of bits to represent the presence or absence of a value in each row. Each bit corresponds to a row in the table, and its value (0 or 1) indicates whether the row contains a specific value for the indexed column.
Databases use these bitmaps to run efficient queries using bitwise operations. It is much quicker to combine bitmaps using ANDs and ORs!
Many modern databases like Postgres provide support for BitMap indexes.
Sorted String Table or SSTable
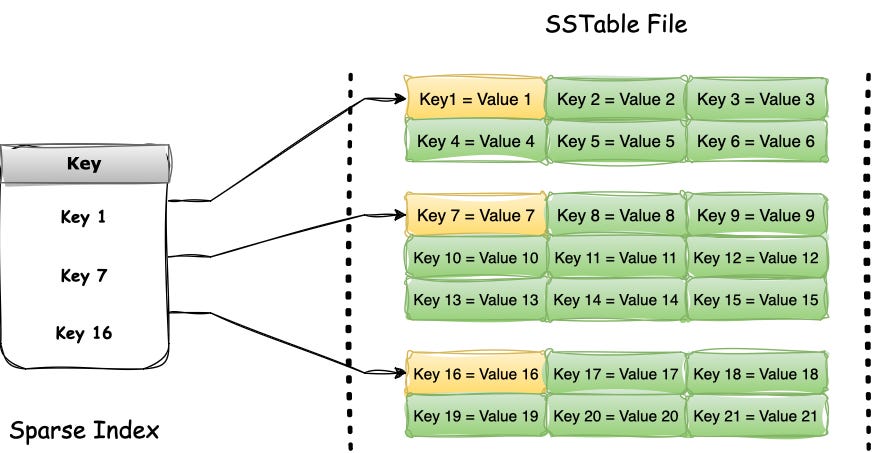
Sorted String Table (SSTable) is a persistent file format that maintains sorted data. It is created using the data from in-memory MemTables and is then persisted on disk as immutable files.
Spare hash indexes are often used to ensure fast searches through SST Files.
SSTable and MemTable together forms the basis of LSM-Tree based databases that are commonly found in many NoSQL databases like Cassandra, ScyllaDB, and RocksDB.
Prefix Trees

Prefix Tree (or, as they popularly known as, Trie) is a data structure optimised to work with strings or text-based data. It creates a tree structure out of a text corpus and use it to perform efficient prefix searches.
Databases like Elasticsearch use Trie for building their inverted index structures.
Write Ahead Log (or WAL)
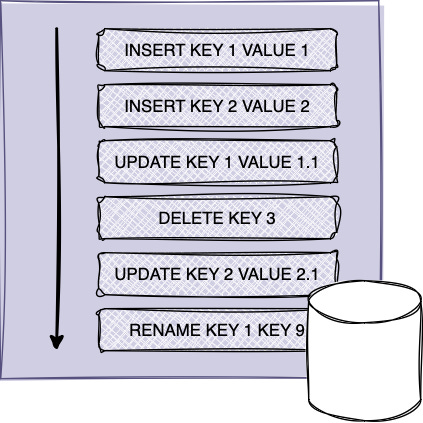
Write Ahead Log is one of those data structures that is equally popular between SQL and NoSQL databases. At its core, it is a simple append-only log of changes that are made to a database.
WAL ensures data durability and can be used to restore state during any catastrophic events. It is also used to buffer writes to database since actual writes to database are often performed in batches at some time later.
Databases like Postgres, RocksDB, and MySQL, all use a WAL under the hood.
Suffix Trees

Suffix tree is yet another advanced structure that is used for full-text search capabilities. It is used to search for the occurrence of a pattern in a large corpus of text efficiently.
Database engines like Elasticsearch and SQLite FTS that supports full-text searching capabilities makes heavy use of such trees.