
15 Databases, 15 Use Cases — The Ultimate Guide That No One Asked For (But Everyone Needs)
Stop Using the Wrong Database for the Right Problem!

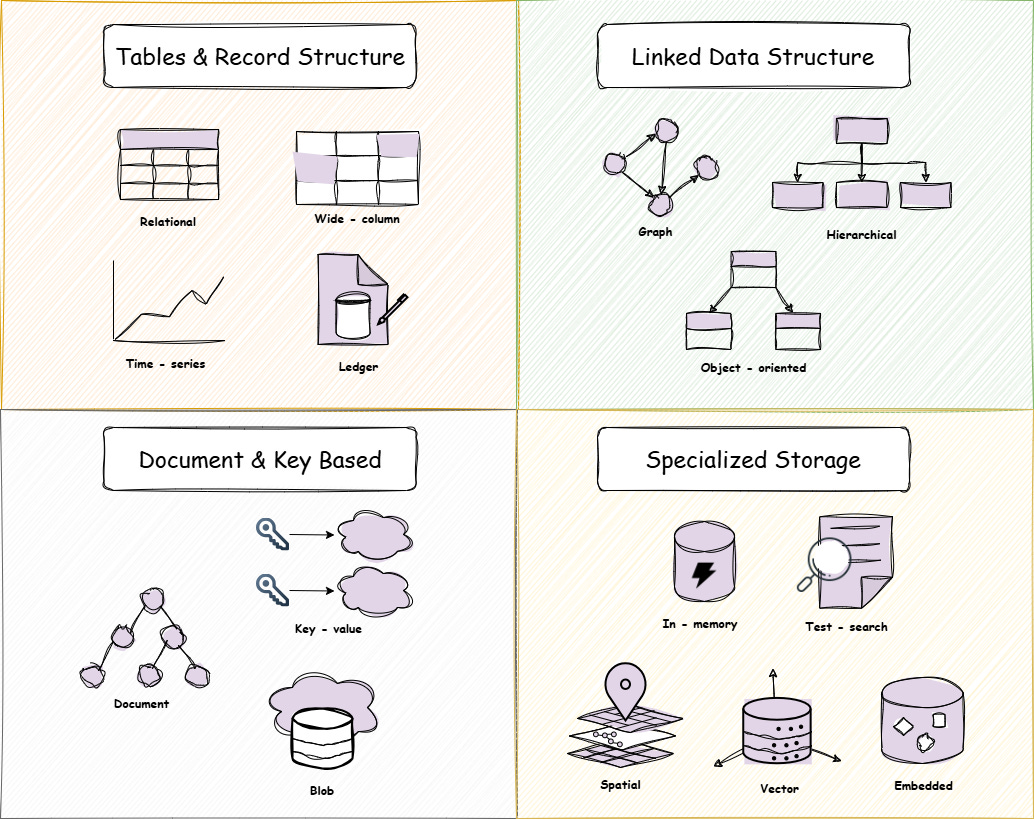
Relational Database
Relational databases are incredibly popular because of their structured nature, ability to manage large amounts of data, and well-established ecosystem! Data is organised into tables with columns of fixed data type. Relationships between rows are established using Foreign Keys (FKs).
These databases are well-suited for structured data with well-defined relationships, maintaining data-integrity, and constraints!

Example: Postgres, MySQL, Oracle, etc.
Some common use cases of Relational Databases are as follows ~
E-Commerce — Tracking customer data, orders, and inventory
Finance — For managing transactions, account details, etc.
Healthcare — Maintaining patient records, appointments, and billing information
Wide Column Database
Wide-Column databases are NoSQL databases that stores data in flexible columns that can be spread across multiple servers or database nodes. Though they might feel similar to relational databases, they are actually very different from them! Here, the name and format of the columns can vary across rows, even within the same table.
Such databases offer low-latency querying speeds, high scalability, and a flexible data model. They are well-suited for cases where writes far exceed reads, data is rarely updated, and there is no need for joins or aggregate.

Example: Cassandra, ScyllaDB, DynamoDB, etc.
Some common use cases of Wide Column Databases are as follows ~
Big-data and analytics
High-write throughput
Time-Series Database
Time-Series databases (TSDB) are optimised for measurements sampled and aggregated over time. Examples of time-series data includes server metric, application performance monitoring, network data, sensor data, events, clicks, trade in market, and many more!
A TSDB is responsible for managing data life-cycle, summarisation and large range scan of many records. They also support time-series aware queries.

Example: InfluxDB, Prometheus, Kdb+, etc.
Some common use cases of Time-Series Databases are as follows ~
Financial Trading Platforms
Performance and Application Monitoring
Ledger Database
Ledger databases are designed pre-dominantly for accounting data. It can store events and historical value of a company’s financial data. While small companies can do away with other database technologies, large companies with high frequency and volumes of financial transactions require a purpose built database like Ledge database.
Key features of ledger databases include immutability and cryptographically verifiable log of data changes. Transactions are validated by a central authority and stored using digital signatures.

Example: Amazon Quantum
Some common use cases of Ledger databases are as follows ~
Financial Applications
Supply Chain Management
Voting Systems
Graph Database
As the name suggests, graph databases store data as nodes, relationship, and properties. Designed for structureless data, graph databases are good for things like social networks and geo-spatial data.
Leveraging the graph structure, graph databases enable efficient traversal, querying, and analysis of interconnected data.

Example: Neo4j, ArangoDB, Amazon Neptune, etc.
Some common use cases of Graph Databases are as follows ~
Social Networks
Knowledge Graphs
Recommendation Systems
Object Oriented Database (ODBMS)
Object-Oriented databases (ODBMS) draw their inspiration from OOP. They store data as objects, similar to how certain programming languages manage data. Data objects in ODBMS encapsulate complex data structures and their associated actions.
Such databases can easily represent intricate data models without requiring multiple tables & joins. They heavily make use of inheritance and polymorphism.

Example: ObjectDB, db4o, etc.
Some common use cases of Object-Oriented Databases are as follows ~
Object-Oriented Applications
Multi-Media Databases
Hierarchical Database
A Hierarchical database is a DBMS that organises data in a tree-like structure, with records connected by link. Each record has single parent record, but can have multiple children records.
Hierarchical databases were commonly used in the early days of computing, where their tree-like structure was well-suited for organizing file systems with directories and files. However, over time, they have been largely supplanted by more flexible database models, such as relational and NoSQL databases, which provide better support for complex relationships and greater overall versatility.

Example: IBM IMS, Windows Registry, etc.
Some common use cases of Hierarchical Databases are as follows ~
File Systems
Document Database
Document databases are used to store & query data as JSON like documents. Flexible, semi-structured, and hierarchical in nature, document database offers ease of development and performance at scale.
Most of the web-applications that communicate using JSON find it very natural to integrate document databases as the data format conversion is not required.

Example: MongoDB, ArangoDB, CouchDB
Some common use cases of Document Databases are as follows ~
Content Management Systems
E-Commerce Platform
Key-Value Database
Key-Value stores are NoSQL database that stores data as collection of key-value pairs. They are well-suited for applications that require fast response and serve high volumes of data.
They are easy to scale and support flexible schema. Their most common use case is for caching.

Example: Couchbase, DataStax, Redis
Some common use cases of Key-Value databases are as follows ~
Application Level Caching
Session Storages
Blob Database
Blob databases are used for storing unstructured data in binary format. Such databases are most suited for storing media files and documents.
Blob databases are optimised for storing large amounts of data that do not fit into standard database schemas.

Example: Amazon S3
Some common use cases of Blob databases are as follows ~
Multi-media storage for applications
Content Delivery Networks
In-Memory Database
These are purpose-built databases that rely primary on internal memory for data-storage. They strive to achieve minimum response time by eliminating disk accesses.
In-Memory databases are most suited for applications that require microseconds response time or have large spikes in traffic. They offer low latency, high throughput, and high scalability.

Example: Redis, Memcached, Apache Ignite, Aerospike, Hazlecast
Some common use cases of In-Memory Databases are as follows ~
Caching
Real-time bidding
Gaming Leaderboard
Text Search Database
Text Search databases are meant for storage, retrieval, and analysis of large volumes of textual data efficiently. They support complex text queries and inverted indexes.

Example: Elastic Search
Some common use cases of Text Search Databases are as follows ~
Web Searches
Auto-Complete and Recommendations
Filtering
Spatial Database
Spatial Databases enhance traditional database functionality to manage complex spatial data types — like points, lines, polygons, and other geometric shapes — along with their related attributes and relationships.

Example: PostGIS, Oracle Spatial, SpatiaLite
Some common use cases of Spatial Databases are as follows ~
Geo-Information Systems
Location Based Services
Spatial Analysis
Vector Database
Vector databases are used to store, index, and search high dimensional data points called vectors. Vectors are used to represent a number of things from numerical features, embeddings from texts/images, and complex data like molecular structures.
These databases use advanced indexing techniques for fast retrievals and similarity searches. They are often optimised for AI and machine learning use-cases.

Example: Pinecone, Chroma
Some common use cases of Vector Databases are as follows ~
Image and Video Search
Recommendation Systems
Embedded Database
Embedded databases are lightweight, specialized databases built directly into software applications, offering seamless integration. Unlike traditional client-server databases that operate as separate processes, embedded databases run within the application itself, enabling faster data access, a smaller footprint, and easier deployment.
These databases are especially valuable in environments with limited resources, where the complexity and overhead of a full client-server database would be unnecessary or impractical.

Example: SQLite, RocksDB, BerkeleyDB
Some common use cases of Embedded Databases are as follows ~
Desktop Applications
Quick Proof-Of-Concepts
With this we reach the end of this blog. If you enjoyed reading this piece, consider clapping and leaving a comment below!