


Airbnb recently released the design of their Mussel key-value store, which they use to serve petabytes of derived data. Their design walks us through the evolution of the key-value store at Airbnb and also gives us a sneak peek into the solution they arrived at and the improvements they are targeting in the future!
In this article, I aim to provide a clear and comprehensive summary of the system they built, highlighting key design decisions and features. If you’d like to explore the original article further after reading my summary, I’ve included a link to it at the end of this post.
Requirements to Satisfy
At Airbnb they have a lot of derived data. It is the data produced after processing through services like Hadoop and Kafka streams, and is often stored offline in data warehouses.
Hundreds of services inside Airbnb require low-latency access to this offline data. To meet this need, they built a unified solution that could be used across all services.
[Version 1] HFileService: Read-only Key-Value Store
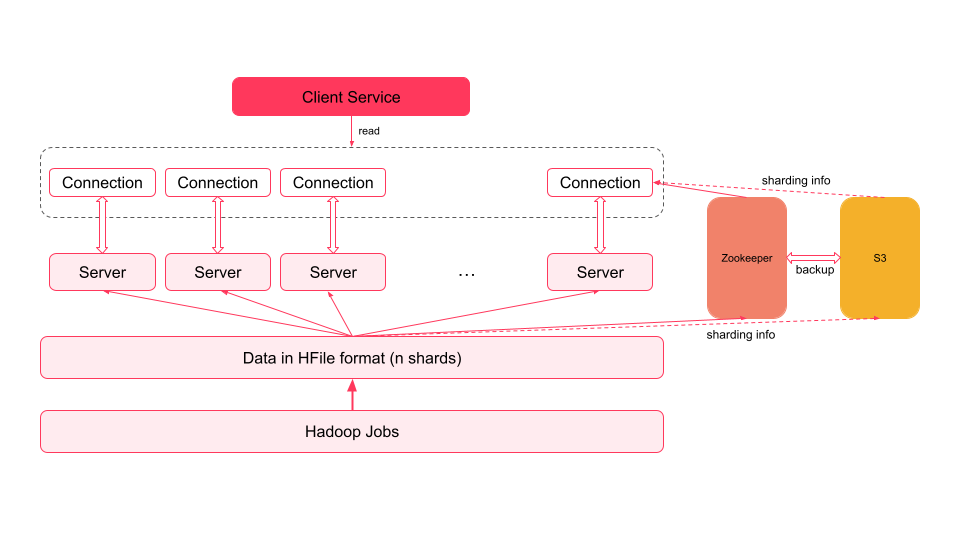
They started by building a read-only key-value store that could serve the derived data from these data warehouses. The goal was to allow scaling to petabytes of data, offer efficient bulk loading, offer low latency reads, and be a multi-tenant storage service that can be used by multiple customers.
None of the existing database could satisfy all of their needs and thus they went ahead with a custom solution called HFileService.
The HFileService consisted of a daily Hadoop Job that took the data out of data warehouses and dumped it to S3 buckets in HFile format.
ⓘ HFile is the name of the file format that is internally used by HBase to store its own data!
The data of the HFile was then split into n shards. These n shards were distributed among a number of servers and the mapping between shards and server was stored inside Zookeeper.
Every day, the servers would pick the data for their respective shards from the remote S3 storage and update their local disks by removing the old data.
A client that needs to read some data would first check the Zookeeper to identify the servers containing the data and would then make a follow up request to any one of them.
[Version 2] Nebula: HFileService with Real-Time Updates
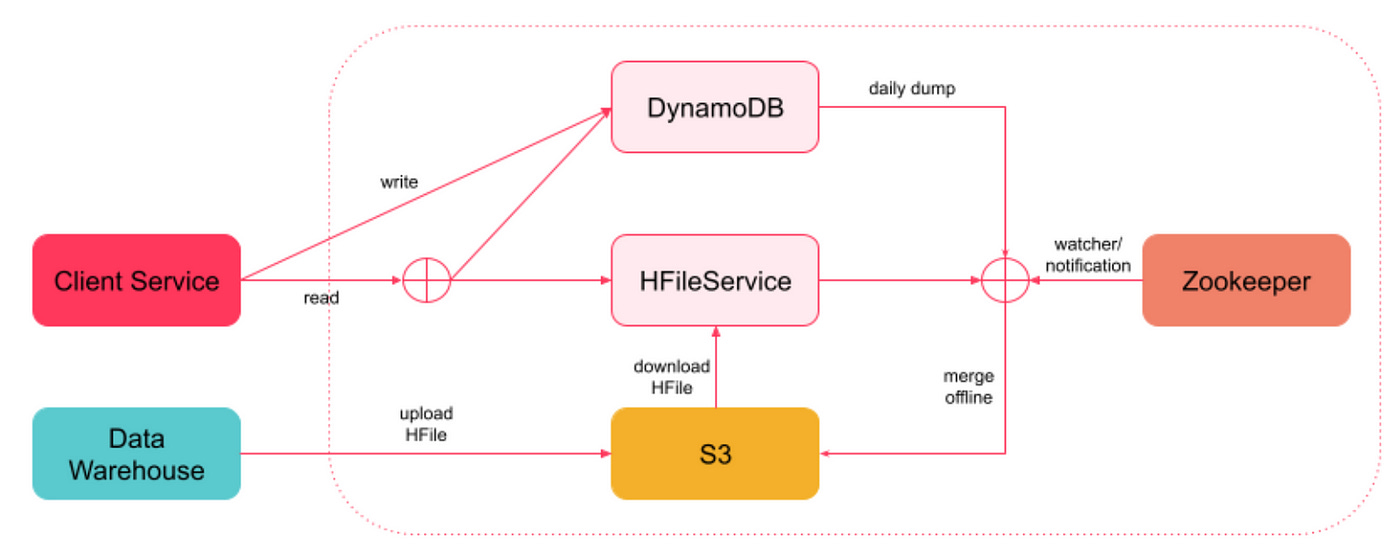
HFileService worked well for the purpose it was designed but a few new requirements showed up later. There was no support for real-time updates! Thus, any new change would only be visible after the daily sync. This lead to the development of the next version of HFileService called Nebula.
The goal with Nebula was to support both batch-updates and real-time updates in a single system. As a result DynamoDB was added to the HFileService. Any real-time write request from client is served by the DynamoDB.
For read requests from client, data is read from both the HFile and the DynamoDB and is then merged based on timestamps.
A background job runs periodically to merge data between HFiles and DynamoDB and create updated HFiles on HFileService servers.
[Version 3] Mussel
While Nebula solved the real-time updates issue, there were still some other problems like ~
Need for manually changing shard to server mapping in Zookeeper
Maintaining HFiles and DynamoDB added to operations cost
Inefficient merging process
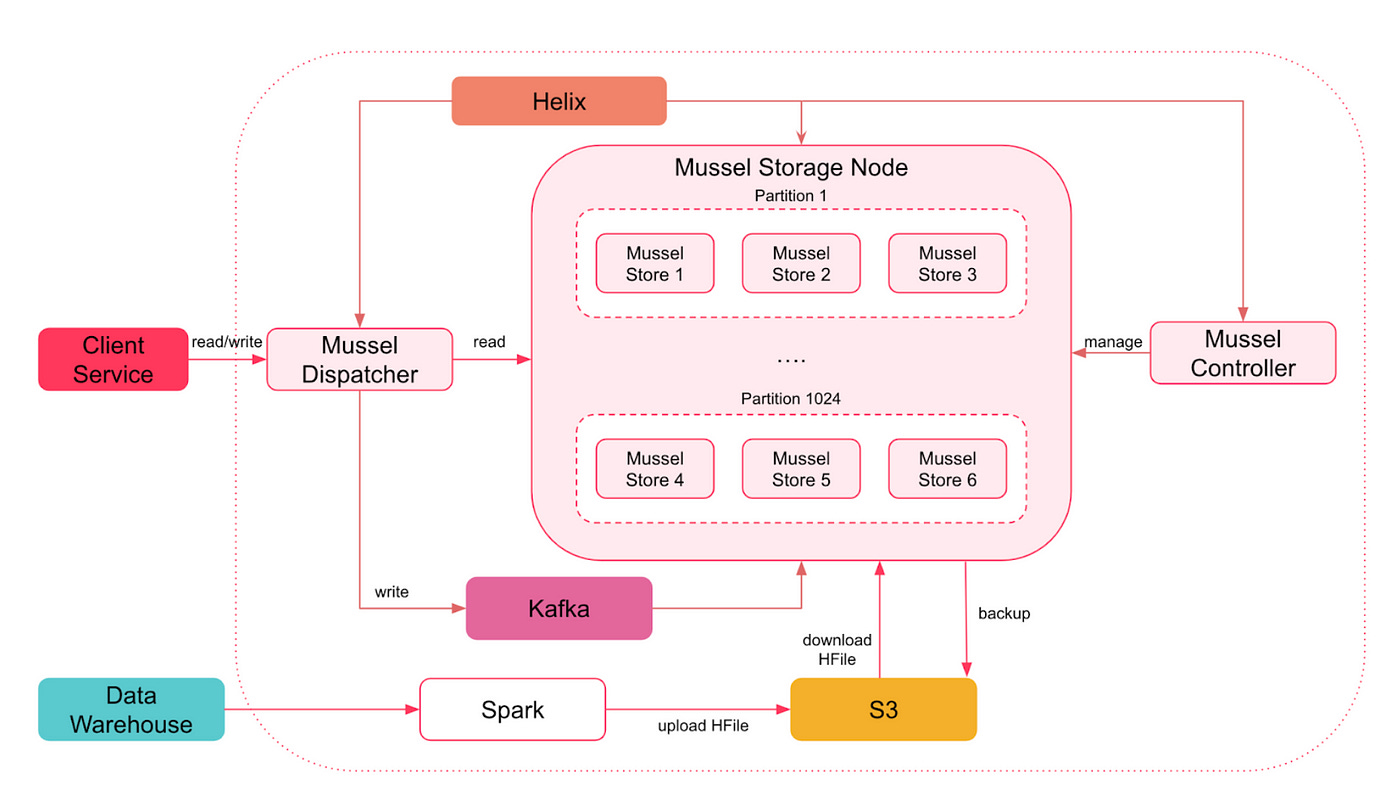
To solve these problems, Mussel as a solution was developed. A number of open source technologies like Apache Helix, Apache Kafka, HRegion, and Spark were used in building this solution.
Just like in the previous two solutions, there were several physical nodes that constituted the database. DynamoDB and HFile were removed and instead HRegion was introduced as the only storage engine in Mussel. Each physical node had HRegion running locally.
ⓘ HRegion is a fully functional key-value store that is internally powered by LSM trees.
Mussel was designed to work with much larger number of shards (1024) then there were in the HFileService (8). The assignment of logical shards to actual server was done using Apache Helix. Each shard was replicated across different nodes for fault-tolerance and reliability.
Since Airbnb had a ready-heavy workload, leaderless-replication was adopted to maintain replicas of a shard. All the write requests are buffered in a Kafka topic and each physical node polls the topic for updates and maintain the replicas they contain. It is important to note that this design supports eventual consistency and not strong consistency.
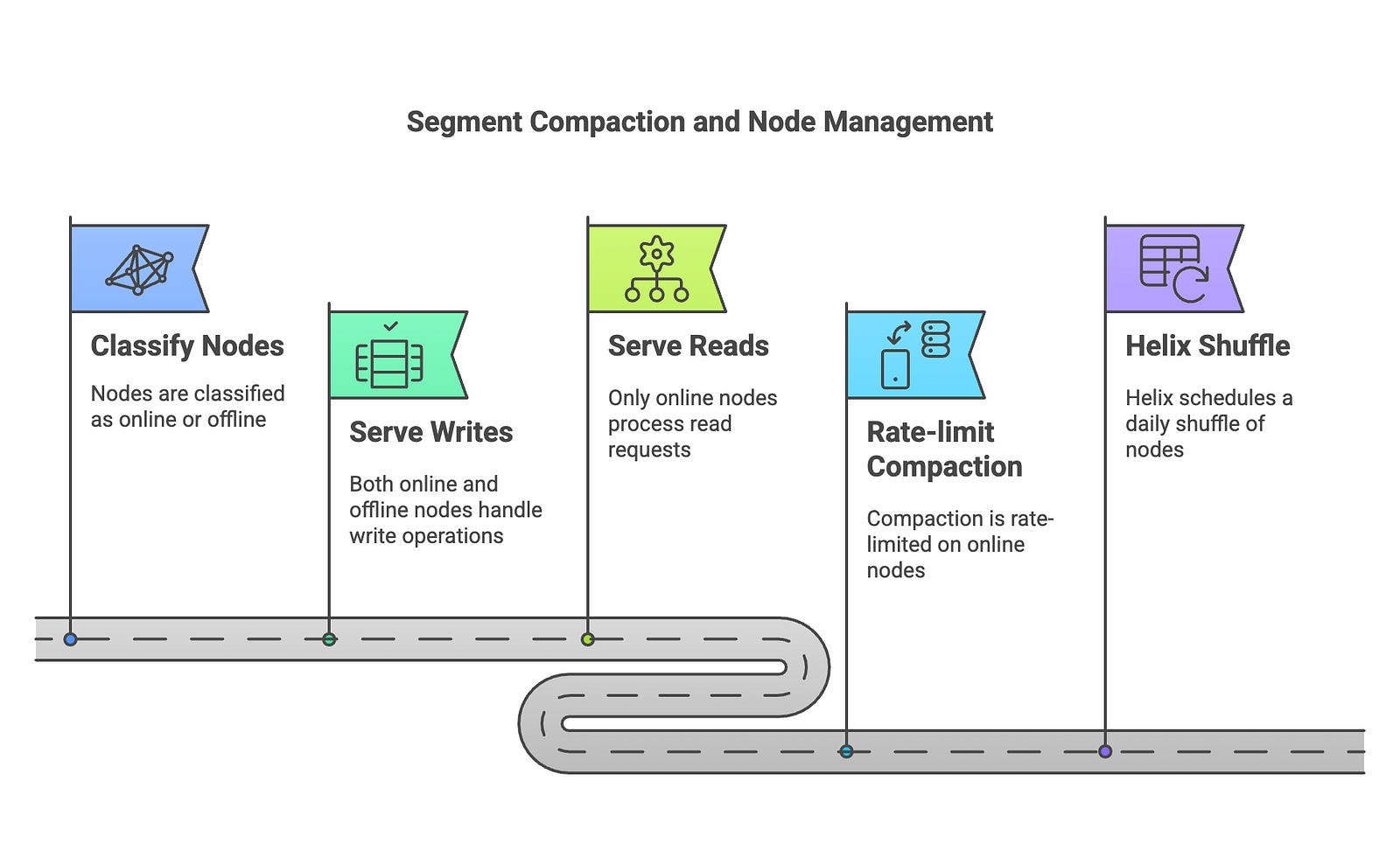
Segment Compaction on Nodes: As HRegion is a LSM-Tree based database, segments on disk needs to be merged and compacted. This merging process can eat up resources on a node and could lead to slower writes and read. To fix this issue, they developed the following mechanism ~
For each logical shard, they classify some replicas as online while others as offline
Both kinds of nodes will serve writes. Reads, however, can only be served by online nodes
Compaction & Merging is rate-limited on online-nodes
Helix schedules a daily shuffle between online and offline nodes
The last piece in the puzzle is the bulk load functionality. Mussel utilises Spark to transform data from the data warehouse into HFile format and upload it to S3. Each Mussel storage node download these files and uses HRegion’s bulkLoadHFiles API to upload deltas. This saves them a ton of costs.
Future Improvements
Mussel is not the end of story. There are still quite a few things that the Airbnb’s engineering team is looking to improve on. This include things like ~
Ensuring read-after-write consistency
Enabling auto-scaling based on cluster’s traffic
And that is all you need to know about Airbnb’s Mussel store that serves petabytes of data! If you are looking for a more in-depth analysis, check out the original blog by Airbnb here.
Here are some more deep-dives that you will enjoy reading!
