
How Pinterest Leverages Kafka for Scalable Long-Term Data Storage and Processing?
Architecture for Storing Petabytes (PB) of Data Using Kafka Tiered Storage


Tired of reading? Enjoy this AI generated podcast of this blog!
Pinterest extensively uses their Kafka pipelines to transfer petabytes of data everyday, causing an ever growing need for them to scale the storage of their Kafka cluster.
The storage capacity of a Kafka cluster can be increased by either horizontally or vertically scaling the Kafka brokers. While horizontal scaling can be achieved by adding more Kafka brokers to the cluster, vertical scaling requires replacing existing brokers with brokers of higher storage capacities.

Both of these scaling methods require copying data between brokers and could take long durations depending on the amount of data copied. Horizontal scaling also add extra CPU and memory that might not be needed.
A cheaper alternative is to store broker’s data on a cheap remote storage like Amazon S3. This allows the broker to keep less data on expensive local disks, reducing the overall storage footprint and cost of Kafka cluster.
Storing recent data on the broker’s local disk while offloading older data to remote storage aligns with the Tiered Storage strategy. Kafka 3.6.0+ offers a built-in solution for implementing Tiered Storage.
The implementation offered by Kafka involves broker interacting with the remote storage for transferring and fetching topic data. This design always has the Kafka broker in active path.
The native implementation has integrated Tiered storage directly into the Kafka broker, which makes it work very efficiently and with better coordination with Kafka’s internal systems.
However, this tight integration means that the broker is always involved in data retrieval (even when the data is stored in cheaper remote storage), limiting the ability to offload work from the broker or serve data directly from the remote storage.
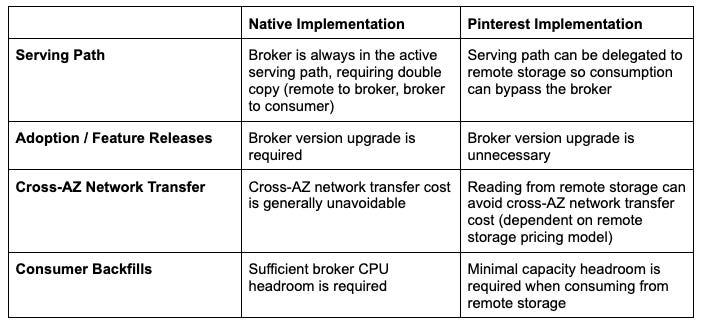
Pinterest’s engineering team developed a broker-decoupled alternative for Kafka Tiered Storage and has open-sourced their implementation on a GitHub repository.
Design & Implementation
The broker-decoupled implementation for Kafka Tiered storage consists of three main components ~
Pinterest Tiered Storage Segment Uploader
Pinterest Tiered Storage Consumer
Remote Storage
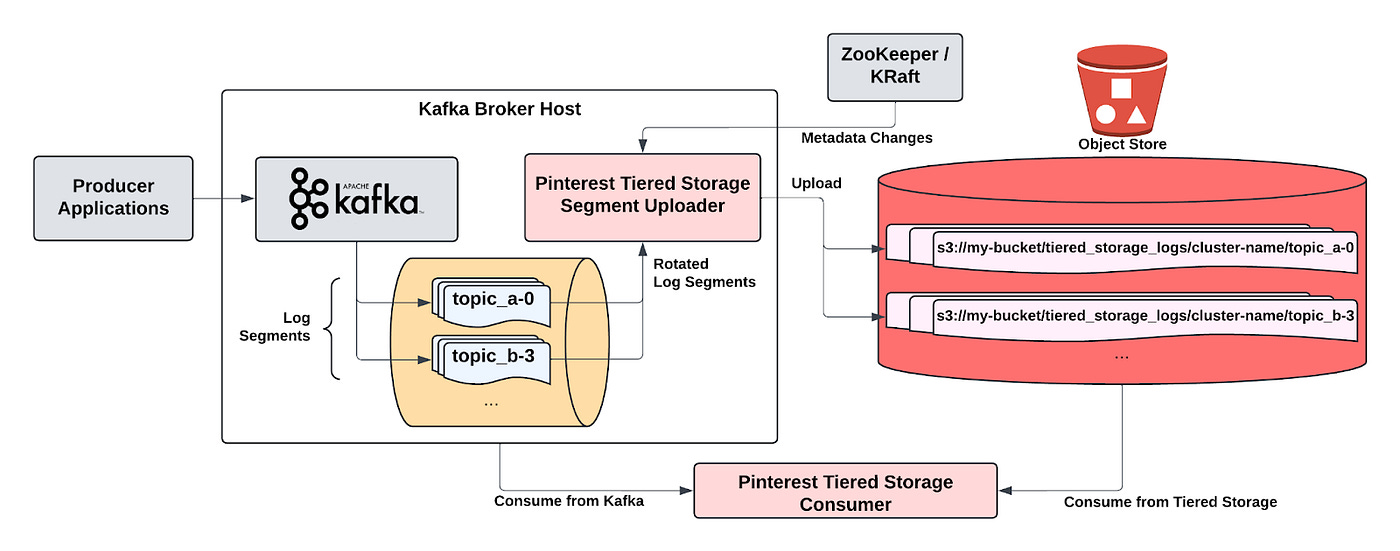
Segment Uploader
The Segment Uploader is an independent process that runs along side the main Kafka broker process as a sidecar. It is responsible for uploading finalised log segments for the partitions that the broker leads to the remote storage.
To achieve its working, the segment uploader has 3 main mechanism ~
Log directory monitoring
Leadership change detection
Fault tolerance
Segment uploader needs to monitor the log and detect when a segment file is ready for upload.
The main Kafka broker process writes data to a local directory specified by the broker configuration log.dir. This is how the log directory looks like.
<log.dir>
| - - - topicA-0
| - - - 00100.index
| - - - 00100.log
| - - - 00100.timeindex
| - - - 00200.index
| - - - 00200.log
| - - - 00200.timeindex
| - - - 00300.index ← active
| - - - 00300.log ← active
| - - - 00300.timeindex ← active
| - - - topicA-3
| - - - <ommitted>
| - - - topicB-1
| - - - <ommitted>
| - - - topicB-10
| - - - <ommitted>
…This directory contains all the topic partitions that this broker is a leader or follower of. The top level folder name contains the name of the topic and the partition number. The underlying files each correspond to one segment. The filename correspond to the earliest offset contained in the segment.
Incoming data is written to the active log segment, which is the segment with the largest offset value.
Using file system events, segment uploader finds out when a log segment is finalised and is ready for upload. Once the segment is uploaded, an offset.wm file is also uploaded to record the latest successful commit.

The Segment Uploader monitors ZooKeeper/KRaft for leadership changes and uploads data only for partitions where the current broker holds leadership.
It is important for the Segment Uploader to be fault tolerant since missed uploads causes data loss. Thus data should be uploaded in a fault-tolerant manner.
There are several reasons because of which a fault can happen ~
Transient Upload Failures — Handled using uploader level retry mechanism.
Broker or Segment Uploader Unavailability — It can be mitigated using the committed offset kept in the
offset.wmfile.Unclean Leader Election — An issue at the broker level, so need not be handled at segment uploader level.
Log Segment Deletion Due to Retention
The last case is the most interesting and the challenging one! Since the segment uploader is an independent entity, it might happen that the broker deletes a segment file before it can be uploaded by the uploader.
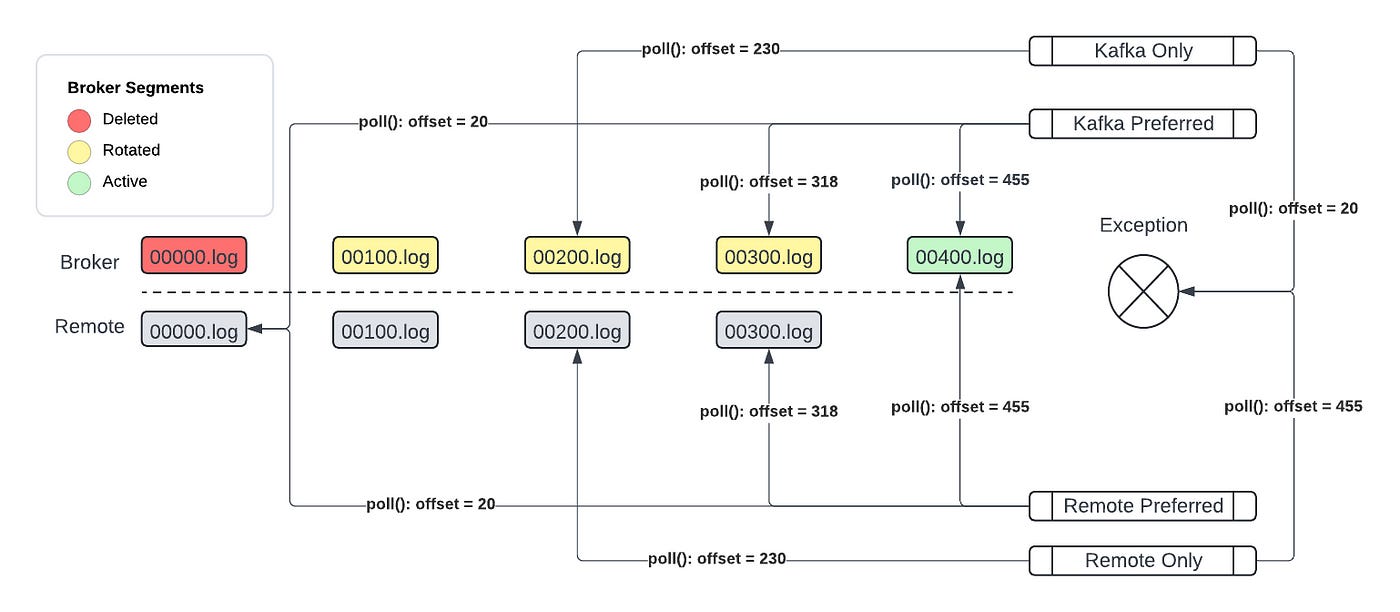
A segment file goes through 4 stages in its lifecycle — Active, Rotated, Staged for delete, and Deleted. The timings of each stage depends on a number of factors.

The segment uploader needs to upload the segment file while it is in Rotatedor Staged for delete stage.
Once the retention period gets over, the Kafka broker storage stages the segment for deletion by appending a .deleted suffix to the segment filename, and remains in this stage for the duration specified by broker config log.segment.delete.delay.ms (defaults to 60 seconds).
In normal usages, the segment uploader does not have any problem as it will have a few minutes window to upload the segment file.
But, when segments are rotated not due to file size but due to retention period, they are immediately moved to Staged for delete from Active. This leaves an even narrower window for uploader to upload segment files.
Broker staged for delete time should be increased to 5 minutes to leave a larger window for uploader. This is a heuristic based approach that worked well for Pinterest team.
Tiered Storage Consumer
The main advantages of de-coupled Kafka Tiered Storage is realised at the consumer. Tiered Storage Consumer is a client library that wraps native KafkaConsumer client. It delegates operations to either the native KafkaConsumer or the RemoteConsumer depending on the desired serving path and where the data is stored.
Tiered Storage Consumer comes out-of-the box with the capability of reading data from both the remote storage and the broker in a fully transparent manner to the user.
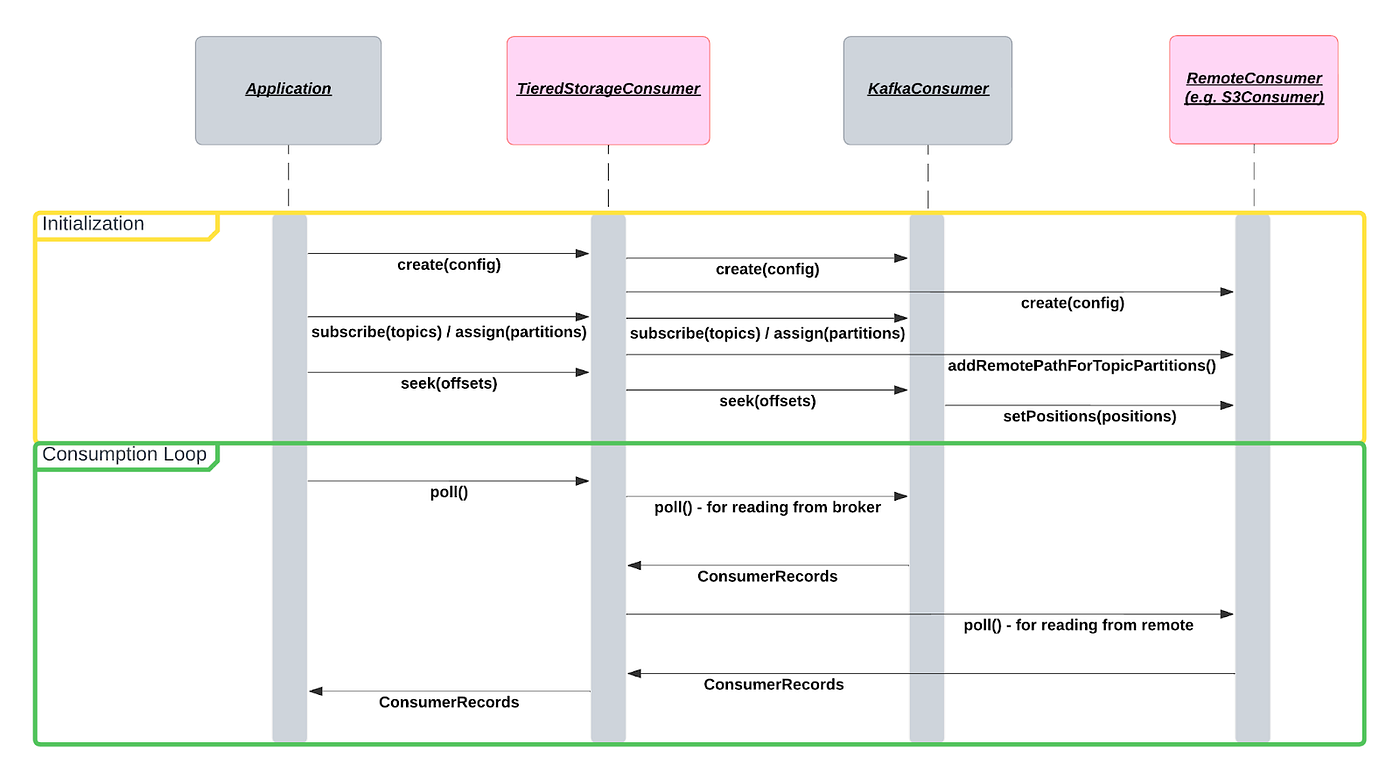
Configurations are provided that consists of native configs + some extra configs specific to Tiered Storage Consumer. Most notably, we need to specify the mode of consumption — Remote Only, Kafka Only, Remote Preferred, and Kafka Preferred.
Consumer leverages the existing functionalities of Kafka’s consumer group management by delegating those operations to KafkaConsumer regardless of its consumption mode.
Clients need to provide our own implementation of StorageServiceEndpointProvider that will help in locating segments on the remote storage. In practice, the same implementation of StorageServiceEndpointProvider should be packaged into the class path of both the Segment Uploader and the consumer application.

Remote Storage
Selecting the right remote storage is very important and requires following considerations ~
Interface Compatibility
Pricing & Mechanism of Data Storage
Scalability & Partitioning
Pre-partitioning of remote storage should be ensured to prevent rate-limiting errors.
With this we reach the end of this article. If you enjoyed reading it, consider leaving a like and comment below!
You will find the original article from Pinterest here.